Xin chào mọi người. Hôm nay chúng ta sẽ cùng tìm hiểu cách để có thể triển khai 1 ứng dụng NodeJS trên EC2 và thông tin dữ liệu được
lưu ở S3 trên AWS nhé!
Mô hình triển khai
Mình sẽ nói qua chút về mô hình triển khai của bài Lab này, yêu cầu của bài lab bao gồm:
- Chuẩn bị EC2 đã được cấu hình IAM Rule truy cập S3
- Cài đặt NodeJS lên EC2
- Lấy code NodeJS truy cập S3 và hiển thị nội dung(danh sách file, ảnh) trong S3 lên web
Chúng ta sẽ đến bài lab ngay bây giờ 😄
1. Chuẩn bị EC2 đã được cấu hình IAM Rule truy cập S3
Trước hết mình đã tạo 1 VPC, với subnet public và subnet private ở bài trước, bạn có thể đọc lại bài VPC trong AWS của mình
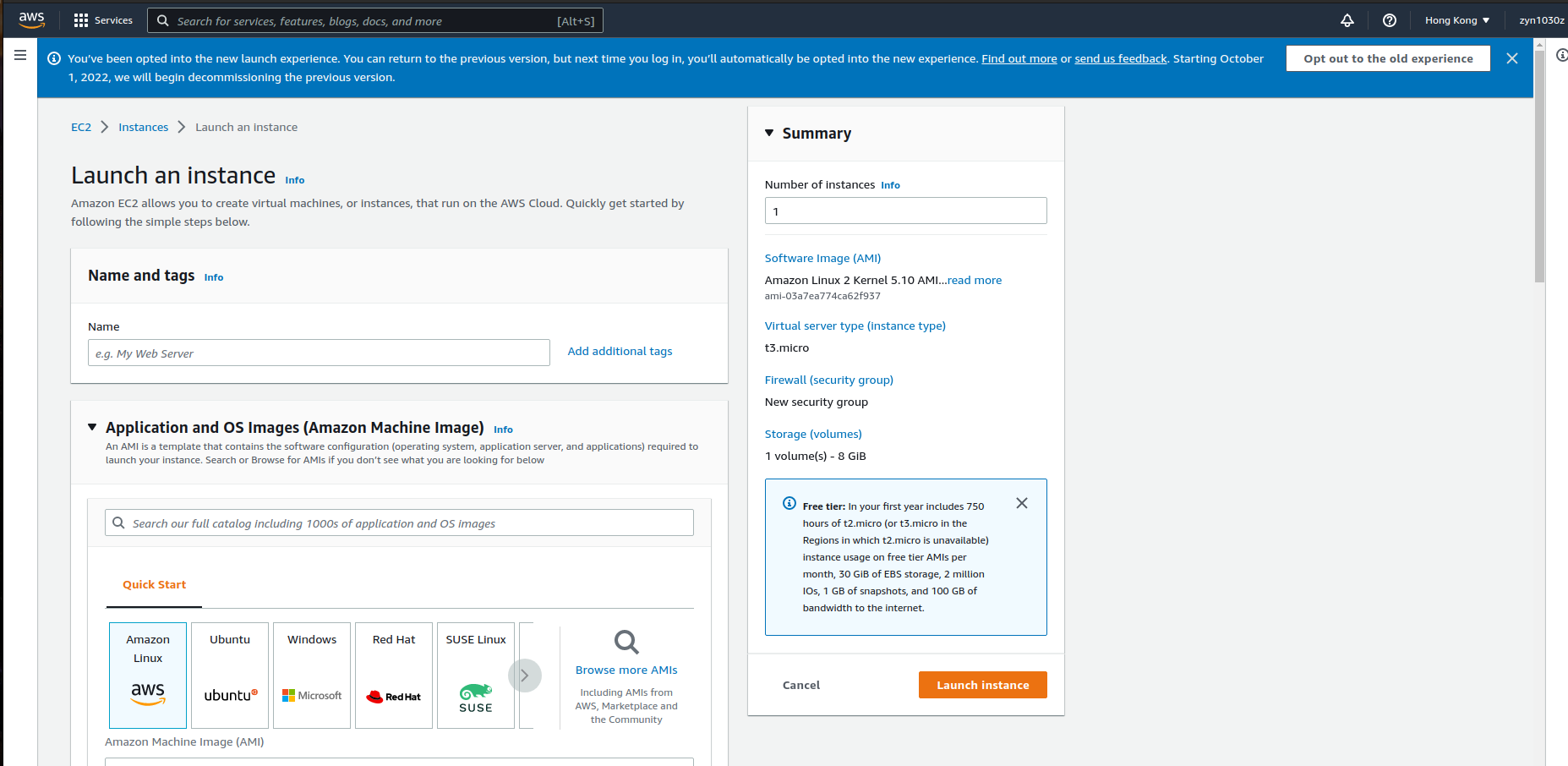
Bước 1: Tạo EC2, S3 Bucket với giao diện AWS Console
Chúng ta lần lượt tạo EC2 và S3 Bucket như sau:
chú ý ở bước tạo Network setting chúng ta sẽ chọn VPC public mà chúng ta tạo ở bài trước
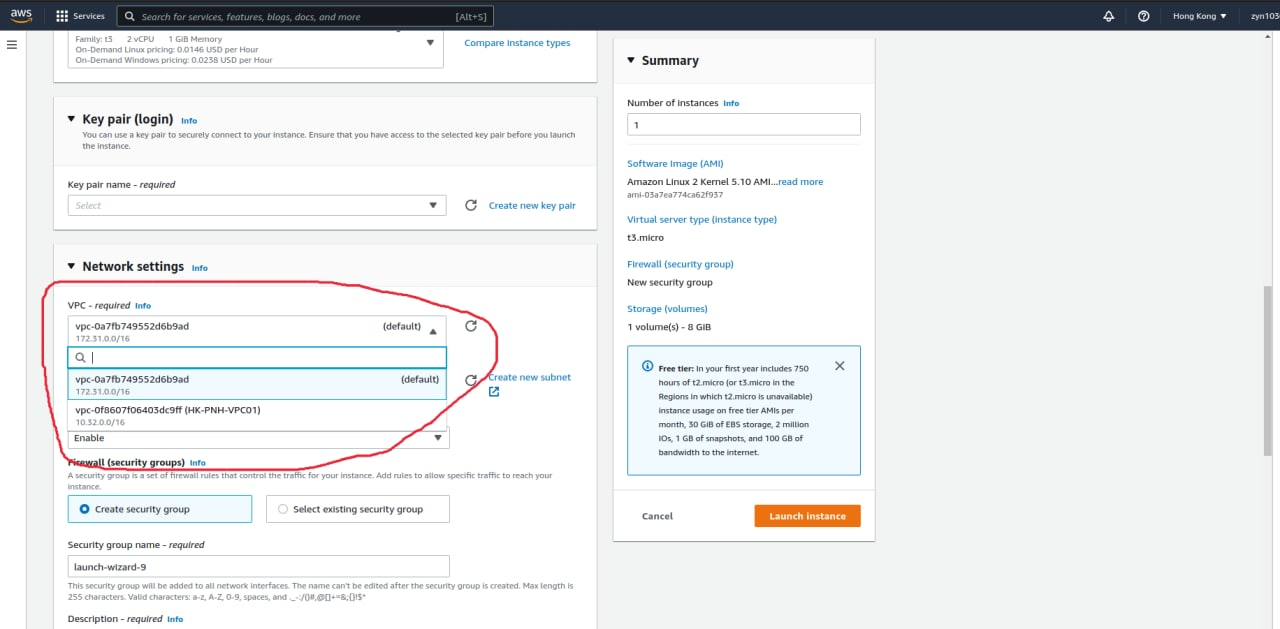
Các bước khác bạn làm tương tự như bài hướng dẫn về EC2
Tiếp theo mình sẽ tạo 1 S3 Bucket, nếu bạn chưa biết S3 Bucket là gì thì S3 Bucket là dịch vụ đám mây lưu trữ do đó bạn có thể tải lên các tệp, các tài liệu,
các dữ liệu tải về của người dùng hoặc các bản sao lưu.
Để hiểu về Amazon S3, bạn cần nắm 1 số khái niệm cơ bản:
- Amazon S3 lưu trữ dữ liệu như các object trong các bucket. Một object gồm 1 file và metadata mô tả cho file (tùy chọn).
- Để lưu 1 object trong Amazon S3, bạn tải file lên 1 bucket. Khi đã tải file, bạn có thể gán quyền cho đối tượng cũng như bổ sung metadata.
- Bucket là các thùng chứa cho các object. Bạn có thể tạo 1 hay nhiều bucket.
- Với mỗi bucket, bạn có thể điều khiển việc truy xuất đến nó (ai có thể tạo, xóa và xem các object trong bucket), xem nhật ký truy xuất đến bucket và đến các object bên trong, cũng như chọn region mà Amazon S3 sẽ lưu bucket và nội dung trong nó.
- Chú ý là mỗi một tài khoản chỉ tạo được tối đa là 100 buckets, và Bucket có tên là duy nhất
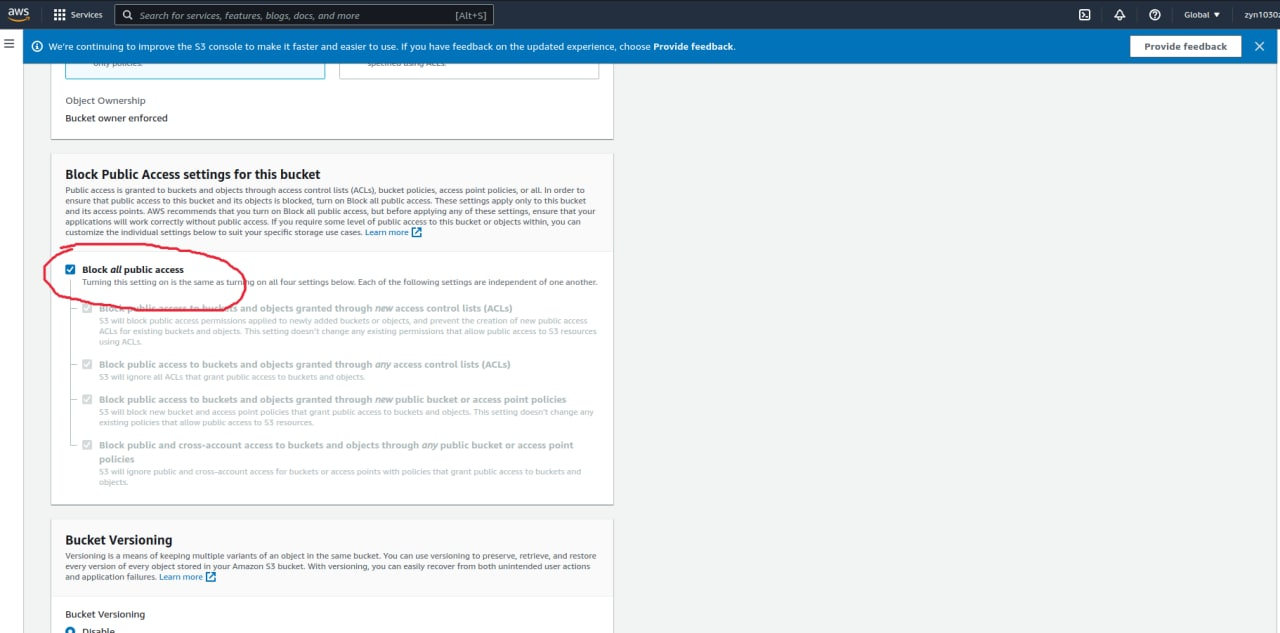
Mình sẽ tạo 1 S3 Bucket như sau:
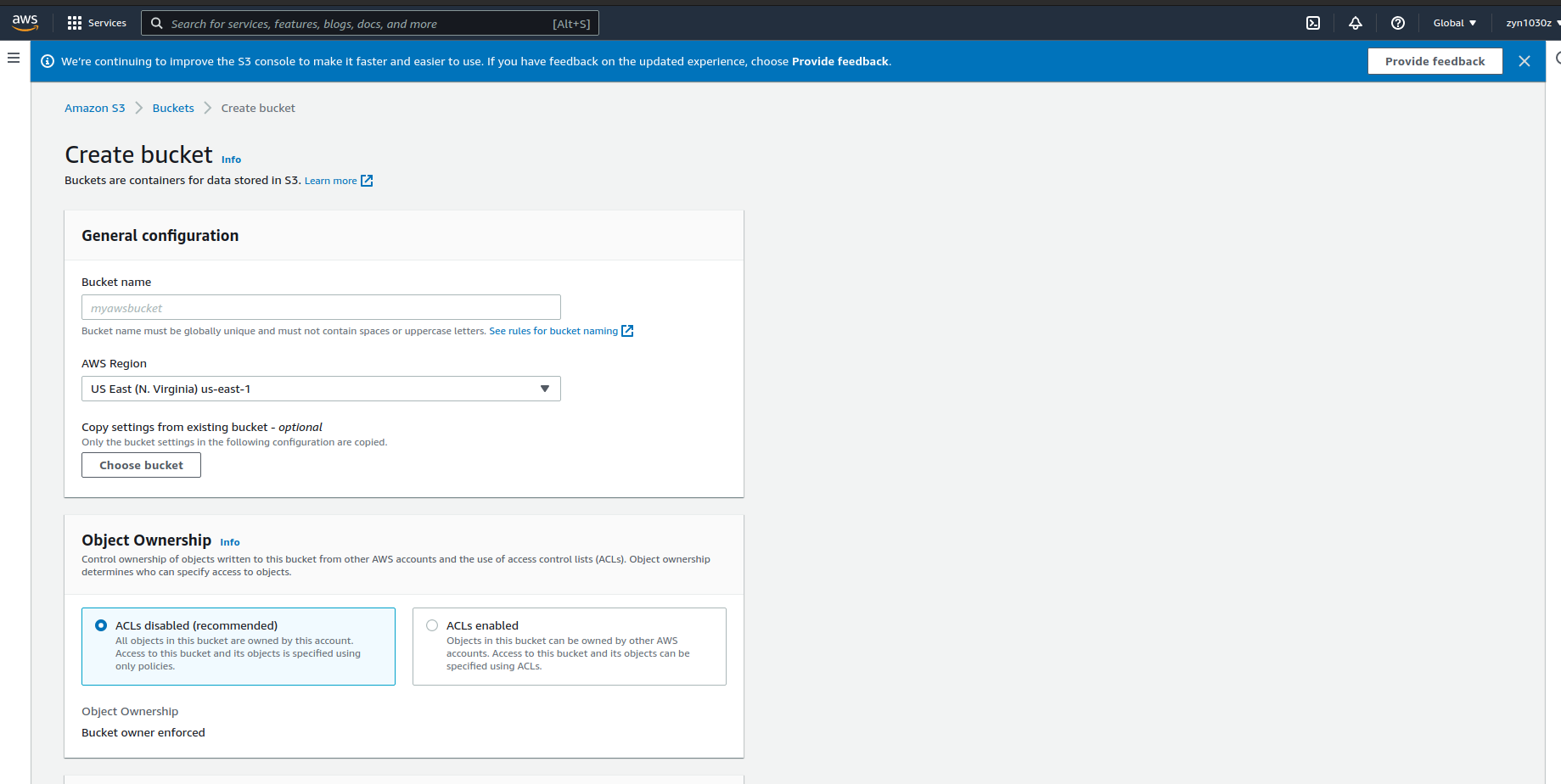
Bạn cần bỏ tích chọn mục này
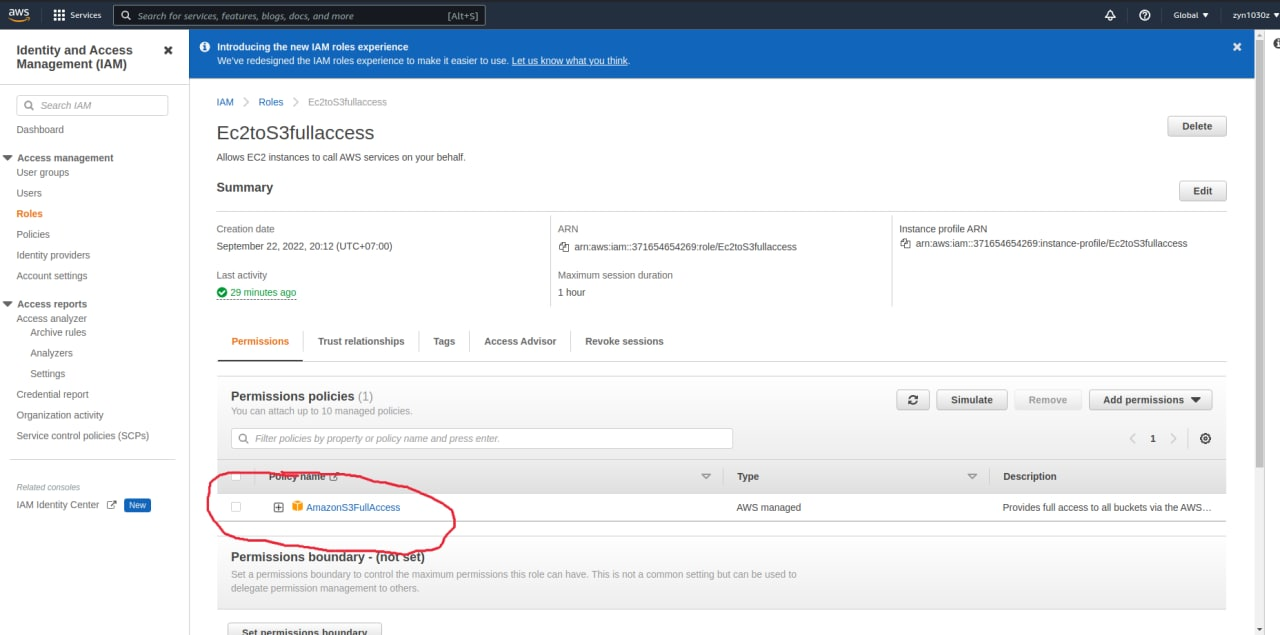
Bước 2: Tạo IAM Role
Tạo 1 rule cho phép EC2 truy cập S3 như sau
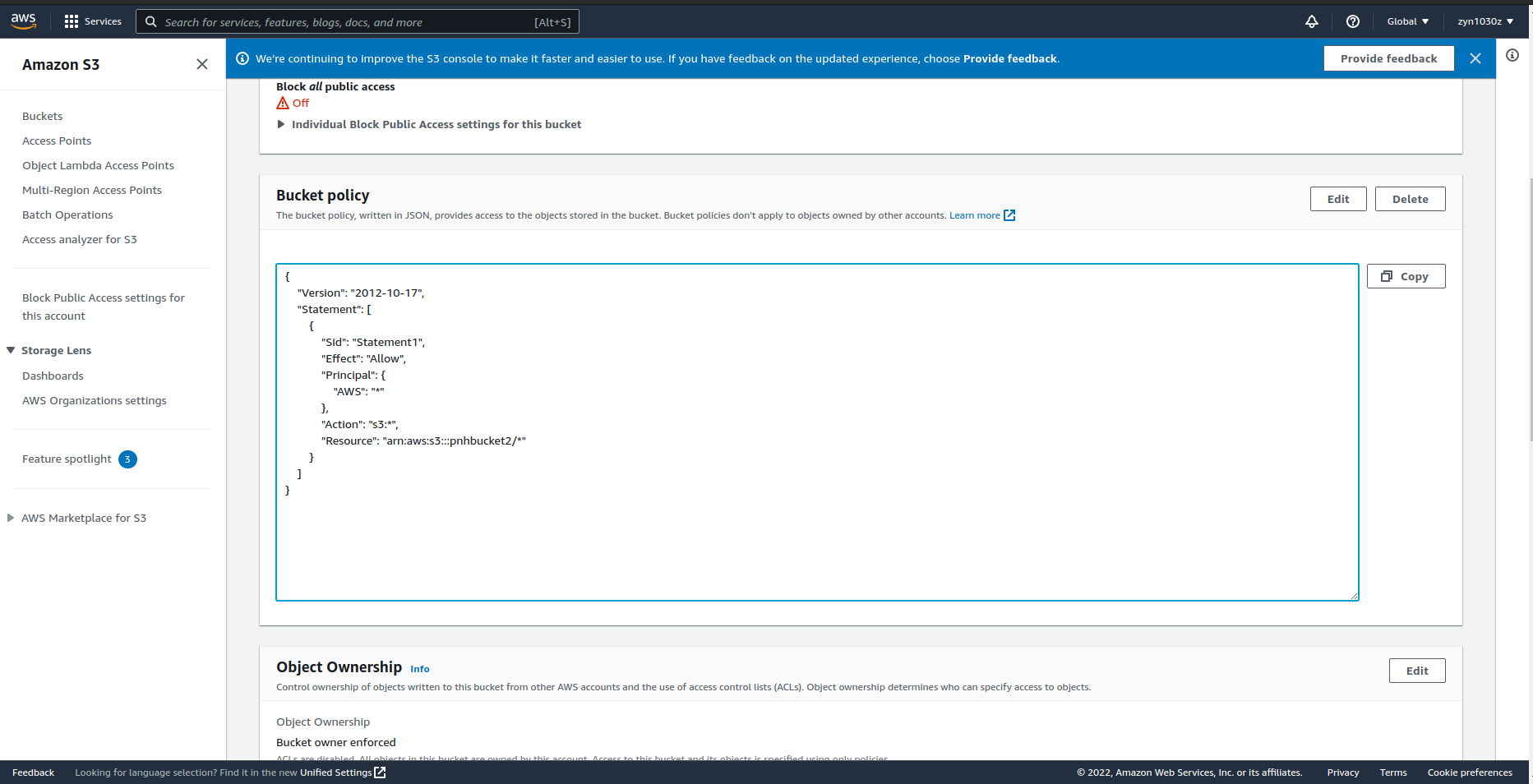
Bước 3: Chỉnh sửa Bucket Policy